

Cómo instalar y usar modelos locales de IA en Alex Sidebar


Marcelo Laprea
19 febrero, 20254min de lectura
En uno de nuestros artículos, aprendimos cómo usar Alex Sidebar en Xcode y todos los beneficios que nos ofrece en el desarrollo de nuestros proyectos. Pero, ¿qué pasa si queremos utilizar modelos de IA locales en lugar de depender de servicios en la nube? En este artículo, te mostraremos cómo instalar y configurar modelos de IA locales en Alex Sidebar.
Pasos a seguir:
- Instalar Ollama.
- Instalar un modelo.
- Instalar ngrok.
- Configurar Alex Sidebar para usar el modelo local.
Instalación de Ollama
Ollama es una herramienta de código abierto que permite ejecutar LLMs de manera local. Para instalarlo, visita su página de descarga y descarga la versión para macOS.
Para ejecutar Ollama, tienes dos opciones:
- Abriendo la aplicación que acabamos de instalar. Una vez abierta, verás el ícono de Ollama en el menú de estado de macOS.

- Ejecutando en la terminal el siguiente comando:
ollama serve
Instalación de un modelo
Con Ollama instalado, el siguiente paso es descargar un modelo. Para ver los modelos disponibles, visita la página de Ollama, donde encontrarás un listado de todos los modelos.
En este artículo, utilizaremos dos modelos:
deepseek-r1
Para instalar este modelo, ejecuta en la terminal uno de los siguientes comandos:
ollama run deepseek-r1:1.5bollama run deepseek-r1:7bollama run deepseek-r1:8bollama run deepseek-r1:14bollama run deepseek-r1:32bollama run deepseek-r1:70b
Donde 1.5b es el modelo más ligero y 70b el más grande. Cuanto mayor sea el modelo, más recursos de memoria requerirá. Se recomienda comenzar con un modelo pequeño y evaluar el rendimiento del sistema.
En nuestras pruebas, usamos el modelo
deepseek-r1:8b.
qwen2.5-coder
Para instalar este modelo, ejecuta uno de los siguientes comandos en la terminal:
ollama run qwen2.5-coder:32bollama run qwen2.5-coder:14bollama run qwen2.5-coder:7bollama run qwen2.5-coder:3bollama run qwen2.5-coder:1.5bollama run qwen2.5-coder:0.5b
En nuestras pruebas, usamos el modelo
qwen2.5-coder:32b.
Comandos útiles de Ollama
- Listar modelos instalados:
ollama list - Eliminar un modelo:
ollama rm <modelo-a-eliminar>
Instalación de ngrok
ngrok es una herramienta que crea un túnel seguro hacia el servidor local, permitiendo exponer los servicios locales a Internet de forma segura. Esto facilita que Alex Sidebar acceda al modelo local como si fuera un servicio en la nube.
Pasos para instalar y configurar ngrok:
- Instalar con Homebrew:
brew install ngrok
- Configurar ngrok con tu token de autenticación:
ngrok config add-authtoken <token>
- Ejecutar ngrok
ngrok http 11434 --host-header="localhost:11434"
Para obtener el authtoken es necesario crear una cuenta en su página oficial.
Configuración de Alex Sidebar para usar el modelo local
Abre la aplicación Alex Sidebar y dirígete a Settings > Models.
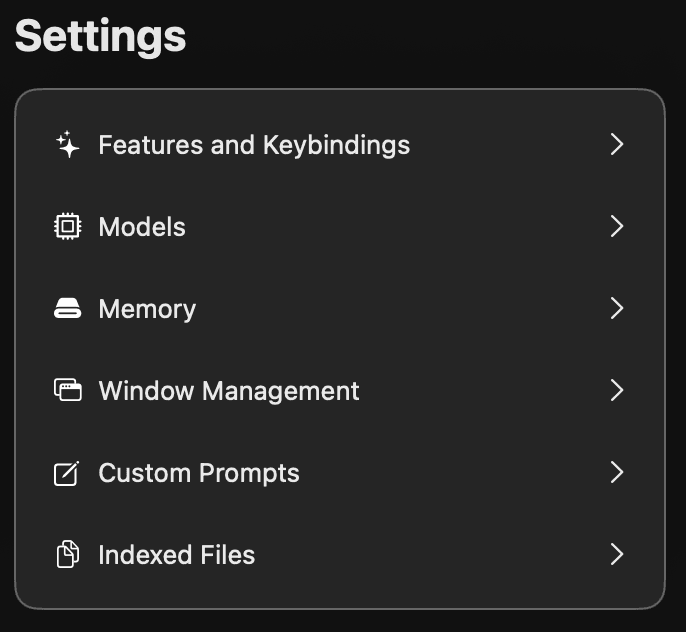
En la parte inferior, encontrarás la sección Custom Models. Haz clic en Add New Model.
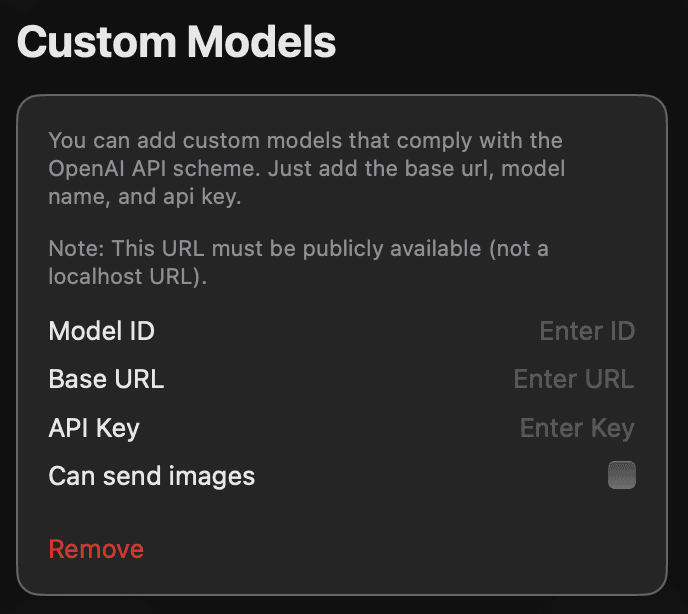
Completa los siguientes campos:
- Model ID: nombre del modelo a usar, por ejemplo:
qwen2.5-coder:32bodeepseek-r1:8b. - Base URL: La URL asignada por ngrok, agregando "/v1" al final. Ejemplo: "https://url.ngrok-free.app/v1".
- API Key: el token de ngrok.
Una vez configurado, podrás seleccionar y utilizar el modelo desde el listado en Alex Sidebar.
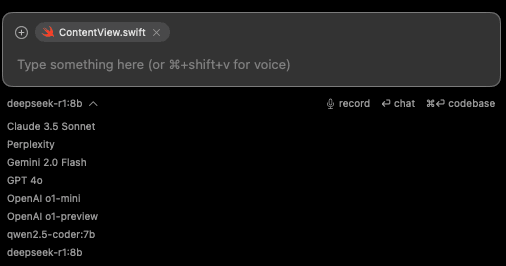
Ahora puedes interactuar con los modelos y realizar prompts, obteniendo respuestas como la siguiente:
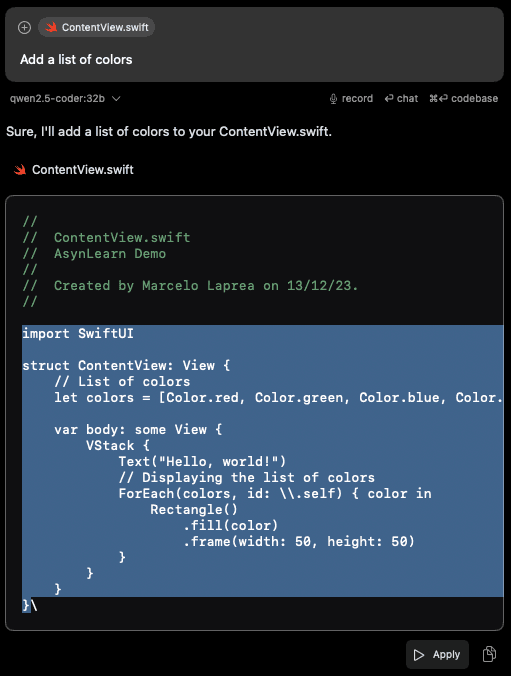
struct ContentView: View {// List of colorslet colors = [Color.red, Color.green, Color.blue, Color.yellow, Color.purple]var body: some View {VStack {Text("Hello, world!")// Displaying the list of colorsForEach(colors, id: \.self) { color inRectangle().fill(color).frame(width: 50, height: 50)}}}}
Si bien este código generó un error en ForEach(colors, id: \\.self), su solución es sencilla y rápida.

Conclusión
Mientras más grande sea el modelo, mejores resultados se obtendrán, aunque también se requerirán más recursos. Un aspecto a considerar al usar modelos locales es que suelen ser más lentos que los servicios en la nube. La elección dependerá de los recursos de tu sistema y del uso que le quieras dar. Ahora es tu turno de probar diferentes modelos y encontrar el que mejor se adapte a tus necesidades.